ChatGPT Image
GPT Image 2 to najpotężniejszy model od OpenAI: 99% celności tekstu, zaawansowane wnioskowanie i do 10 grafik na raz. Sprawdź go teraz na Somake AI.
Generator obrazów AI ChatGPT Image
Ostatnia aktualizacja: 22 kwietnia 2026 r.
Aktualna wersja: GPT Image 2
Starsze wersje są dostępne w panelu po lewej stronie.
Tabela szybkiego przeglądu
| Atrybut | Szczegóły |
|---|---|
| Wersja modelu | GPT Image 2 |
| Producent | OpenAI |
| Data premiery | 21 kwietnia 2026 r. |
| Typ modelu | Generowanie i edycja obrazów (multimodalny) |
| Główne zalety | Niemal idealne renderowanie tekstu, natywne wnioskowanie, rozdzielczość do 4K |
| Najlepszy do | Kreacji marketingowych, infografik, makiet produktów, treści brandingowych, storyboardów |
| Dostępny na Somake | Tak |
Wstęp
W przeciwieństwie do wcześniejszych, samodzielnych narzędzi takich jak DALL-E, ten generator obrazów ChatGPT jest zintegrowany z systemami językowymi i rozumowania OpenAI. Oznacza to, że interpretuje polecenia (prompty) z poziomem zrozumienia kontekstu, któremu poprzednie modele nie mogły dorównać.
Wraz z wersją GPT Image 2 model wprowadza funkcję natywnego wnioskowania – co OpenAI nazywa "trybem myślenia" (thinking mode) – który pozwala mu planować kompozycję, liczyć obiekty i weryfikować ograniczenia układu jeszcze przed wygenerowaniem obrazu. Rezultatem jest znacznie mniej błędów przy złożonych zadaniach oraz ogromny skok w dokładności renderowania tekstu, którą OpenAI ocenia na ponad 99% zarówno dla skryptów łacińskich, jak i niełacińskich. Dla zespołów tworzących masowo kreacje reklamowe, karty produktów czy grafiki instruktarzowe, całkowicie zmienia to pojęcie użyteczności generatorów AI.
GPT Image 2 najlepiej sprawdza się w zastosowaniach komercyjnych i produkcyjnych: treściach markowych, makietach UI, infografikach, układach redakcyjnych i storyboardach. Nie jest to model dedykowany wyłącznie generatorom czysto artystycznym, gdzie liczy się unikalny styl – w takich przypadkach Midjourney wciąż pozostaje preferowanym wyborem.
Co nowego w GPT Image 2
Kluczowe zmiany względem GPT Image 1.5 (grudzień 2025):
Natywne wnioskowanie: Model planuje układ, kompozycję i rozmieszczenie obiektów przed renderowaniem – funkcja aktywna dla płatnych subskrybentów ChatGPT.
Dokładność tekstu: Obsługuje małe etykiety UI, podpisy, skrypty wielojęzyczne (japoński, koreański, chiński, hindi, bengalski) oraz układy z różnymi czcionkami. To ogromny krok naprzód względem wersji 1.5, gdzie tekst był tylko "czasami użyteczny".
Spójność postaci między obrazami: W GPT Image 2 model zachowuje tożsamość postaci – w tym detale takie jak tatuaże i fryzury – na wielu kolejnych klatkach.
Nowa architektura: OpenAI opisuje model jako "zbudowany od zera", z bazą wiedzy do grudnia 2025 roku, co poprawia dokładność odniesień do rzeczywistości.
Wyjście w rozdzielczości do 4K: Obsługuje rozdzielczości do 4096×4096 (max krawędź 3840px). Dobrym sposobem na optymalizację kosztów jest start od niższej jakości i późniejszy upscaling do 4K.
Wyszukiwanie w sieci w trybie myślenia: Model może pobierać obrazy referencyjne i fakty w trakcie generowania, aby zapewnić dokładność diagramów i kontekstu rzeczywistego.
Usunięcie żółtego zafarbu: Uporczywy artefakt z wersji 1.5 całkowicie zniknął w GPT Image 2.
Aktualizacja ta jest milowym krokiem, a nie tylko drobną poprawką. Renderowanie tekstu połączone z wnioskowaniem rozwiązuje dwa największe problemy zgłaszane przez profesjonalistów. GPT Image 1.5 był już sprawny; GPT Image 2 nadaje się do pełnego wdrożenia komercyjnego.
Główne funkcje

Niemal idealne renderowanie tekstu na obrazach
W wersji GPT Image 2 dokładność tekstu w różnych alfabetach i rozmiarach czcionek przekroczyła 99%, wliczając znaki CJK (chiński, japoński, koreański), hindi, bengalski i złożone układy typograficzne. Dzięki temu wygenerowane przez AI materiały marketingowe, menu, etykiety produktów, infografiki i diagramy edukacyjne nadają się do użytku bez konieczności ręcznych poprawek – czego poprzednie modele ChatGPT nie potrafiły zagwarantować.

Wielojęzyczne generowanie obrazów
GPT Image 2 precyzyjnie renderuje niełacińskie skrypty wewnątrz obrazów – nie jest to tylko transliteracja, ale "poprawne renderowanie z zachowaniem płynności językowej", jak podaje OpenAI. Obsługiwane skrypty to między innymi japoński (Kanji/Hiragana/Katakana), koreański (Hangul), chiński uproszczony i tradycyjny, hindi (Devanagari) oraz bengalski. Dla zespołów tworzących lokalne zasoby reklamowe na rynki zagraniczne eliminuje to etap ręcznej korekty tekstu.

Natywne wnioskowanie przed renderowaniem ("Tryb myślenia")
GPT Image 2 to pierwszy model graficzny OpenAI z wbudowanymi zdolnościami "myślenia". Zanim pierwszy piksel zostanie wygenerowany, model planuje kompozycję, weryfikuje liczbę obiektów i sprawdza ograniczenia przestrzenne. W praktyce drastycznie skraca to liczbę powtórzeń (regeneracji) przy złożonych promptach – układach z konkretnym rozmieszczeniem przedmiotów, tabelach z podpisami czy scenach wieloelementowych.
Generowanie wielu obrazów z jednego promptu
Pojedyncze polecenie może wygenerować do ośmiu spójnych wariantów obrazu, dzielących tę samą paletę kolorystyczną, kompozycję i tożsamość postaci. To zastępuje żmudny proces tworzenia pojedynczych grafik dla projektantów, którzy muszą przejrzeć kilka opcji przed wyborem kierunku, oraz dla zespołów tworzących warianty reklam czy klatki do storyboardów.

Spójność postaci i obiektów na różnych klatkach
Począwszy od GPT Image 2, model zachowuje spójną tożsamość obiektu – rysy twarzy, ubranie, fryzurę i charakterystyczne detale, takie jak tatuaże – na wielu wygenerowanych obrazach. Jest to kluczowe przy produkcji storyboardów, arkuszy postaci w tworzeniu gier oraz w każdym przepływie pracy, gdzie ta sama osoba musi pojawić się w całej sekwencji.
Najlepsze zastosowania
Tworzenie kreacji marketingowych i reklam z czytelnym tekstem
Zespoły marketingowe potrzebują obrazów zawierających czytelne nazwy produktów, wezwania do działania (CTA) i hasła reklamowe. W GPT Image 2 elementy te są renderowane na tyle dokładnie, że można ich używać bez konieczności czyszczenia grafiki. Twórz posty do mediów społecznościowych, ulotki i reklamy displayowe, gdzie tekst jest wkomponowany w grafikę – a jeśli potrzebujesz rozdzielczości do druku, możesz zwiększyć skalę obrazu.
Tworzenie infografik, diagramów i grafik edukacyjnych
Połączenie wnioskowania i dokładności tekstu sprawia, że GPT Image 2 jest wyjątkowo skuteczny przy tworzeniu gęstych treści wizualnych: diagramów procesów, wykresów, porównań i etykietowanych map. Tryb myślenia weryfikuje rozmieszczenie obiektów i celność podpisów przed renderowaniem, co ma kluczowe znaczenie, gdy treść musi być merytorycznie poprawna, a nie tylko ładna.

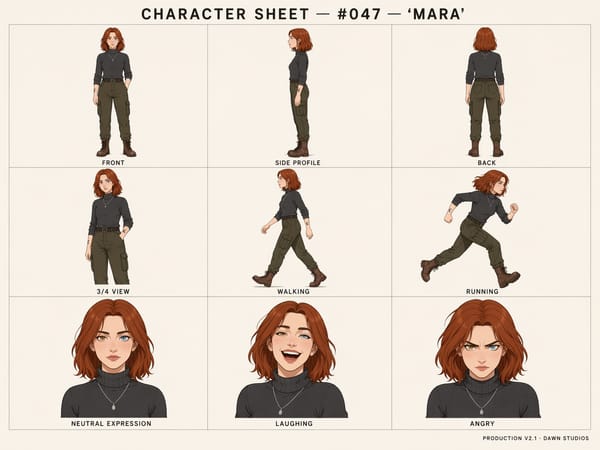
Produkcja storyboardów i arkuszy postaci (Character Sheets)
Spójność postaci to jedna z najbardziej praktycznych nowości w GPT Image 2 dla branży kreatywnej. Wygeneruj pełny arkusz postaci z różnymi pozami i emocjami, używając do 3 obrazów referencyjnych, lub stwórz wielopanelowy storyboard, gdzie ci sami bohaterowie pojawiają się na każdej klatce. Aby uzyskać profesjonalne rezultaty, wypróbuj dedykowany generator arkuszy postaci.

Generowanie zdjęć produktów i makiet opakowań
GPT Image 2 świetnie radzi sobie z fotografią produktową – realistycznym oświetleniem, teksturami powierzchni i czytelnością etykiet na opakowaniach. Twórz projekty pudełek płatków śniadaniowych, butelek leków czy etykiet z prawdziwymi tabelami wartości odżywczych i kodami kreskowymi. Na potrzeby e-commerce możesz potem usunąć tło, aby przygotować plik do wstawienia na stronę sklepu.
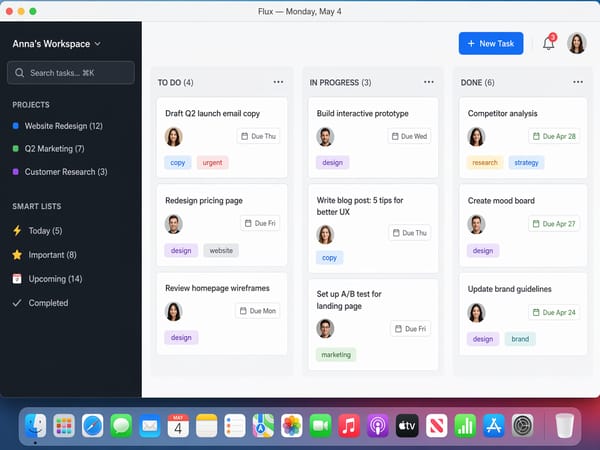
Makiety UI i zrzuty ekranu aplikacji do prezentacji
Model renderuje realistyczne interfejsy aplikacji, widoki stron internetowych i komponenty UI wystarczająco dokładnie, by mogły służyć jako makiety w prezentacjach. Renderowanie fontów, ikonek i logika układu są nadzorowane przez warstwę wnioskowania. Jest to niezwykle przydatne dla product managerów i deweloperów, którzy chcą szybko przetestować wizualny kierunek bez użycia narzędzi graficznych.
Poradnik pisania promptów
Tryb myślenia GPT Image 2 zmienia sposób, w jaki powinniśmy pisać prompty. Model planuje przed generowaniem – co oznacza, że konkretne i szczegółowe wytyczne dają lepsze efekty niż ogólne opisy stylu.
Prompty z tekstem: bądź precyzyjny
Określ styl czcionki, hierarchię wielkości i dokładny tekst, który ma się pojawić. GPT Image 2 radzi sobie z tym świetnie, ale woli jasne instrukcje od domysłów.
Ulotka z wydarzenia, ciemnogranatowe tło, wyśrodkowany biały nagłówek o treści
"DESIGN SUMMIT 2026", pod nim mniejszy szary podtytuł o treści
"30 kwietnia · San Francisco", adres strony w prawym dolnym rogu: "designsummit.co"
Minimalistyczny układ, geometryczne akcenty.Opisuj strukturę, nie tylko temat
GPT Image 2 dobrze reaguje na instrukcje dotyczące kompozycji. Określ, gdzie mają znajdować się obiekty, co ma być w tle i gdzie ma się pojawić tekst. Warstwa wnioskowania rozumie zależności przestrzenne, które wcześniejsze modele często ignorowały.
Zdjęcie produktowe brązowej torby papierowej z kawą kraft, zwróconej przodem, białe tło,
czarna etykieta tekstowa z napisem "Single Origin Ethiopia" czystym fontem sans-serif,
pasek stopnia wypalenia kawy na dole pokazujący "Medium", tabela wartości odżywczych na
bocznym panelu częściowo widoczna z prawej strony. Oświetlenie studyjne, lekki cień.
Unikaj prośby o "większy realizm" bez konkretów
Instrukcja "bardziej realistyczne" nie jest zbyt pomocna dla tego modelu. Zamiast tego opisz, co ten realizm oznacza w Twoim przypadku: typ oświetlenia (złota godzina, studyjne, zachmurzone niebo), materiał powierzchni (matowy, błyszczący, szorstki) lub styl fotograficzny (reporterski, produktowy, dokumentalny).
Aktywowanie trybu myślenia dla złożonych układów
W przypadku infografik, scen z wieloma obiektami oraz wszelkich zadań wymagających policzalnych elementów lub precyzyjnego pozycjonowania, tryb myślenia daje najbardziej niezawodne wyniki. W interfejsie ChatGPT wybierz wariant modelu z funkcją "thinking". Przez API ustaw odpowiednią flagę. Przygotuj się na nieco dłuższy czas generowania – zazwyczaj 1–3 minuty dla złożonych zadań – w zamian za znacznie mniejszą liczbę błędów.
GPT Image 2 vs. Gemini 3 Pro Image
| Funkcja | GPT Image 2 | Gemini 3 Pro Image |
|---|---|---|
| Renderowanie tekstu | Znakomite | Bardzo dobre |
| Wnioskowanie / planowanie układu | Natywne | Dostępne |
| Spójność postaci | Bardzo dobra | Dobra |
| Fotorealizm | Bardzo dobry | Bardzo dobry |
| Zakres stylów artystycznych | Dobry | Dobry |
| Maks. rozdzielczość | 4K | 4K |
| Tekst wielojęzyczny | Znakomity | Bardzo dobry |
| Przestrzeganie instrukcji | Znakomite | Dobre |
| Szybkość (tryb standard) | ~30–60 sekund | ~30 sekund |
Jak używać ChatGPT Image na Somake AI
Przejdź do strony modelu ChatGPT Image na Somake AI i wybierz GPT Image 2 z rozwijanej listy.
Wybierz poziom jakości – niska, średnia lub wysoka. Niska jakość daje solidne efekty przy mniejszym koszcie kredytów i jest idealna na start.
Ustaw proporcje obrazu – wybierz spośród gotowych ustawień (kwadrat, panorama, portret).
Wybierz liczbę obrazów – wygeneruj do 4 obrazów naraz, aby przejrzeć wariacje przed podjęciem decyzji.
Napisz prompt – bądź precyzyjny w kwestii kompozycji, tekstu, oświetlenia i ułożenia przedmiotów. Im więcej szczegółów, tym lepiej.
Wgraj obrazy referencyjne (opcjonalnie) – możesz dodać do 3 obrazów dla edycji, transferu stylu lub zachowania spójności postaci.
Generuj – w trybie standardowym proces zajmuje 30–60 sekund.
Uwaga: Niektóre funkcje natywne (np. tryb myślenia, paczki powyżej 4 obrazów, eksperymentalne 4K) mogą nie być jeszcze w pełni dostępne na Somake. Sprawdzaj kartę modelu na Somake, aby poznać aktualnie obsługiwane parametry.
Historia wersji
| Wersja | Data wydania | Kluczowe zmiany |
|---|---|---|
| GPT Image 2 | Kwi 2026 | Natywne wnioskowanie, niemal idealna dokładność tekstu, spójność postaci, wsparcie dla CJK/Hindi/Bengali, rozdzielczość 4K, usunięcie żółtego zafarbu |
| GPT Image 1.5 | Gru 2025 | 4x szybsze generowanie, lepsze przestrzeganie instrukcji przy edycji, poprawione renderowanie twarzy i kolorów |
| GPT Image 1 Mini | Paź 2025 | Ekonomiczna wersja GPT Image 1 |
| GPT Image 1 | Mar 2025 | Pierwszy natywny model graficzny GPT-4o; zastąpił DALL-E; edycja konwersacyjna, świetne trzymanie się promptu |







