Imagens do ChatGPT
O GPT Image 2 é o modelo de imagem mais avançado da OpenAI: 99% de precisão em textos e até 10 imagens por prompt. Experimente agora no Somake AI.
Gerador de IA Imagens do ChatGPT
Última atualização: 22 de abril de 2026
Versão Atual: GPT Image 2
Versões legadas disponíveis no painel à esquerda.
Tabela de Visão Geral
| Atributo | Detalhes |
|---|---|
| Versão do Modelo | GPT Image 2 |
| Desenvolvedora | OpenAI |
| Data de Lançamento | 21 de abril de 2026 |
| Tipo de Modelo | Geração + edição de imagem (multimodal) |
| Principais Pontos Fortes | Renderização de texto quase perfeita, raciocínio nativo, resolução de até 4K |
| Ideal Para | Materiais de marketing, infográficos, mockups de produtos, conteúdo de marca, storyboards |
| Disponível no Somake | Sim |
Introdução
Diferente de ferramentas isoladas anteriores como o DALL-E, este gerador de imagens do ChatGPT é arquitetonicamente integrado aos sistemas de linguagem e raciocínio da OpenAI. Isso significa que ele interpreta os prompts com um nível de compreensão contextual que os modelos de imagem anteriores não conseguiam alcançar.
A partir do GPT Image 2, o modelo introduz capacidades de raciocínio nativo — o que a OpenAI chama de "modo de pensamento" — que permitem planejar a composição, contar objetos e verificar restrições de layout antes da renderização. O resultado são menos falhas em pedidos complexos e um salto notável na precisão da renderização de texto, que a OpenAI afirma ser superior a 99% tanto para alfabetos latinos quanto não latinos. Para equipes que produzem anúncios, fichas de produtos ou gráficos instrutivos em massa, isso muda o que a geração de imagens por IA pode realmente entregar na prática.
O GPT Image 2 é mais robusto para casos de uso comerciais e de produção: conteúdo de marca, mockups de UI, infográficos, layouts editoriais e storyboards com várias cenas. Ele é menos indicado para gerações puramente estéticas ou de artes plásticas, onde a exclusividade estilística é o objetivo principal — nesses casos, modelos como o Midjourney continuam sendo a preferência.
O que há de novo no GPT Image 2
Principais mudanças em relação ao GPT Image 1.5 (dezembro de 2025):
Raciocínio nativo: O modelo agora planeja o layout, a composição e o posicionamento dos objetos antes de renderizar — ativado para assinantes pagos do ChatGPT.
Precisão na renderização de texto: Abrange desde pequenos rótulos de UI a legendas e alfabetos multilíngues (japonês, coreano, chinês, hindi, bengali), além de layouts com fontes variadas. Uma evolução drástica em relação ao 1.5, onde o texto era apenas "usável às vezes".
Consistência de personagens entre imagens: No GPT Image 2, o modelo mantém a identidade do sujeito — incluindo detalhes como tatuagens e penteado — em vários quadros gerados.
Arquitetura reformulada: A OpenAI descreve o modelo subjacente como "reconstruído do zero", com uma base de conhecimento atualizada até dezembro de 2025 para melhor precisão do mundo real.
Resolução de até 4K: Suporta resoluções de até 4096×4096 (borda máxima de 3840px). Começar com uma qualidade menor e fazer o upscale depois é um jeito econômico de chegar ao 4K.
Pesquisa web no modo de pensamento: O modelo pode buscar imagens de referência e fatos durante a geração para garantir a precisão de diagramas e contexto real.
Eliminação do tom amarelado: Um artefato persistente nas imagens do 1.5 que foi corrigido no GPT Image 2.
O upgrade é substancial — não apenas incremental. A renderização de texto e o raciocínio resolvem os dois maiores obstáculos para o uso profissional. Se o GPT Image 1.5 já era capaz, o GPT Image 2 é comercialmente implementável para uma gama muito maior de tarefas.
Recursos Principais

Renderização de texto quase perfeita em imagens geradas
Com o GPT Image 2, a precisão do texto em diferentes alfabetos e tamanhos de fonte ultrapassou 99%, incluindo caracteres CJK (chinês, japonês, coreano), hindi, bengali e layouts com misturas de fontes. Isso torna materiais de marketing, menus, rótulos, infográficos e diagramas educativos gerados por IA prontos para uso sem necessidade de retoques manuais — algo que os modelos anteriores de geração de imagem do ChatGPT não entregavam com confiança.

Geração de Imagens Multilíngues
O GPT Image 2 renderiza alfabetos não latinos com precisão dentro das imagens — não apenas transliterados, mas "renderizados corretamente com uma linguagem que flui de forma coerente", segundo a OpenAI. Os alfabetos suportados incluem japonês (Kanji/Hiragana/Katakana), coreano (Hangul), chinês simplificado e tradicional, hindi (Devanagari) e bengali. Para equipes que produzem ativos criativos localizados para diferentes mercados, isso elimina a etapa de correção manual de textos não latinos.

Raciocínio Nativo Antes da Renderização ("Modo de Pensamento")
O GPT Image 2 é o primeiro modelo de imagem da OpenAI com capacidades de pensamento integradas. Antes do primeiro pixel ser renderizado, o modelo planeja a composição, verifica a contagem de objetos e checa as restrições espaciais. Na prática, isso reduz o número de tentativas em prompts complexos — layouts com posicionamento específico de objetos, grades com conteúdo rotulado e cenas com múltiplos elementos que modelos antigos costumavam montar errado.
Geração de Lote Multi-Imagens a partir de um Único Prompt
Um único prompt pode gerar até oito variações coerentes de imagem, compartilhando a mesma paleta, composição e identidade do personagem. Isso substitui o fluxo de trabalho de geração única e repetitiva para designers que precisam revisar opções antes de escolher um caminho — e para equipes que produzem variantes de anúncios ou quadros de cenas para storyboards.

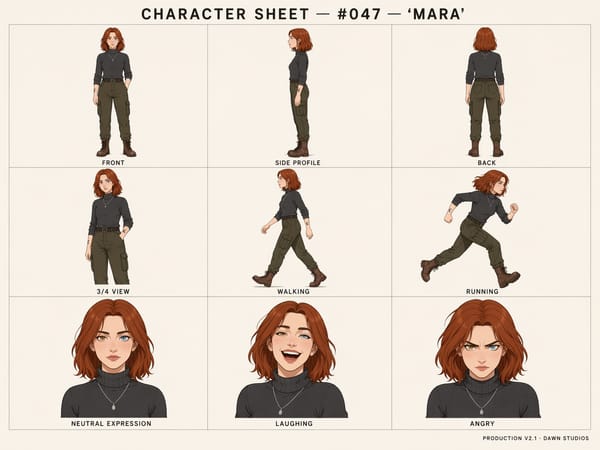
Consistência de Personagem e Sujeito entre Quadros
A partir do GPT Image 2, o modelo mantém a identidade consistente do sujeito — características faciais, roupas, penteado e detalhes específicos como tatuagens — em várias imagens geradas. Isso é essencial para produções de storyboards, fichas de personagens para games e qualquer fluxo de trabalho que precise da mesma pessoa ou objeto aparecendo em uma sequência.
Melhores Casos de Uso
Criação de Materiais de Marketing e Anúncios com Texto Legível
Equipes de marketing precisam de imagens que incluam nomes de produtos, CTAs e slogans legíveis. No GPT Image 2, esses elementos são renderizados com precisão suficiente para uso em produção. Gere posts para redes sociais, panfletos e banners onde o texto já vem pronto na imagem — e use o nosso upscaler de imagem se precisar de resolução para impressão.
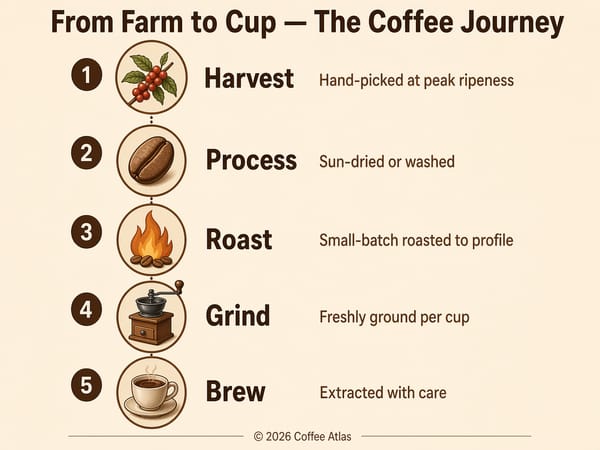
Criação de Infográficos, Diagramas e Gráficos Educativos
A combinação de raciocínio e precisão de texto do GPT Image 2 o torna capaz de criar conteúdos visuais densos: diagramas de processos, explicativos baseados em dados, tabelas comparativas e mapas rotulados. O modo de pensamento verifica o posicionamento dos objetos e a precisão dos rótulos antes de renderizar, o que é crucial quando o conteúdo precisa ser factual e não apenas bonito.

Produção de Storyboards e Fichas de Personagem
A consistência de personagens entre quadros é uma das atualizações mais práticas do GPT Image 2 para a produção criativa. Gere uma ficha completa com várias poses e expressões usando até 3 imagens de referência, ou produza um storyboard de vários painéis onde os mesmos personagens aparecem de forma consistente. Para saídas estruturadas, experimente o nosso gerador de ficha de personagens.

Geração de Fotos de Produtos e Mockups de Embalagens
O GPT Image 2 lida bem com cenários de fotografia de produtos — iluminação realista, texturas de superfície e legibilidade de rótulos. Crie caixas de cereais, frascos de medicamentos ou rótulos de produtos prontos para apresentação, com informações nutricionais e códigos de barras precisos. Para e-commerce, você pode remover o fundo após a geração para preparar o ativo para o seu site.
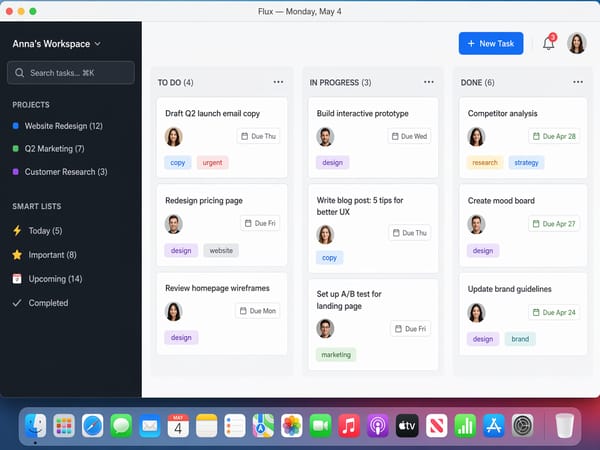
Mockups de UI e Prints de Apps para Apresentações
O modelo renderiza interfaces de aplicativos realistas, capturas de tela e componentes de UI com precisão suficiente para protótipos de apresentação. A renderização de fontes, o posicionamento de ícones e a lógica de layout são tratados pela camada de raciocínio. Isso é muito útil para gerentes de produto e desenvolvedores testando direções visuais sem ferramentas de design.
Guia de Prompts
O modo de pensamento do GPT Image 2 mudou a forma de escrever prompts. O modelo planeja antes de renderizar — o que significa que comandos detalhados e específicos produzem resultados melhores do que direções estilísticas vagas.
Prompts com Texto na Imagem: Seja Explícito
Especifique o estilo da fonte, a hierarquia de tamanho e as frases exatas que deseja renderizar. O GPT Image 2 lida com isso de forma precisa, mas se beneficia de instruções claras em vez de apenas sugerir onde o texto deve ficar.
Panfleto de evento, fundo azul marinho escuro, título centralizado em branco escrito
"DESIGN SUMMIT 2026", subtítulo abaixo em texto cinza menor escrito
"30 de Abril · San Francisco", URL do site no canto inferior direito: "designsummit.co"
Layout minimalista, formas geométricas de destaque.Descreva a Estrutura, não apenas o Assunto
O GPT Image 2 responde bem a instruções de composição. Diga onde os objetos devem estar, o que há no fundo e qual texto deve aparecer em cada lugar. A camada de raciocínio interpreta restrições espaciais que modelos anteriores ignoravam.
Foto de produto de um saco de café de papel kraft marrom, de frente, fundo branco,
rótulo de texto preto escrito "Single Origin Ethiopia" em uma fonte sans-serif limpa,
barra indicadora de nível de torra na parte inferior mostrando "Média", rótulo nutricional
no painel traseiro parcialmente visível na borda direita. Iluminação de estúdio, sombra leve.
Evite pedir "Mais Realista" sem detalhes
"Mais realista" não é um comando muito útil para este modelo. Em vez disso, descreva o que realismo significa para você: tipo de iluminação (golden hour, estúdio, nublado), material da superfície (fosco, brilhante, rugoso) ou estilo fotográfico (editorial, fotografia de produto, documental).
Ativando o Modo de Pensamento para Layouts Complexos
Para infográficos, cenas com muitos objetos e qualquer prompt que exija contagem de elementos ou posicionamento preciso, o modo de pensamento produz resultados mais confiáveis. Na interface do ChatGPT, selecione a variante do modelo de pensamento. Via API, ative a flag de thinking na sua requisição. Espere um tempo de geração maior — normalmente de 1 a 3 minutos para tarefas de raciocínio complexas — em troca de menos erros.
GPT Image 2 vs. Gemini 3 Pro Image
| Recurso | GPT Image 2 | Gemini 3 Pro Image |
|---|---|---|
| Renderização de texto | Excelente | Forte |
| Raciocínio / planejamento de layout | Nativo | Disponível |
| Consistência de personagem | Forte | Boa |
| Fotorrealismo | Forte | Forte |
| Variedade de estilos artísticos | Boa | Boa |
| Resolução máxima | 4K | 4K |
| Texto multilíngue | Excelente | Forte |
| Seguimento de instruções | Excelente | Bom |
| Velocidade (modo padrão) | ~30–60 segundos | ~30 segundos |
Como usar as Imagens do ChatGPT no Somake AI
Vá até a página do modelo Imagens do ChatGPT no Somake AI e selecione GPT Image 2 no menu suspenso de modelos.
Escolha o nível de qualidade — Baixa, Média ou Alta. A qualidade Baixa entrega ótimos resultados com menor custo de créditos e é um bom ponto de partida.
Defina a proporção da tela — escolha entre os presets disponíveis (quadrado, paisagem, retrato).
Defina a quantidade de imagens — gere até 4 imagens por vez no Somake para revisar variações antes de escolher.
Escreva seu prompt — seja específico sobre composição, texto, posição dos objetos e iluminação. Prompts detalhados funcionam melhor.
Faça o upload de imagens de referência (opcional) — anexe até 3 imagens para edições, transferências de estilo ou consistência de personagem.
Gere — o modo padrão leva de 30 a 60 segundos.
Nota: Alguns recursos nativos do modelo — incluindo o modo de pensamento, geração em lote acima de 4 imagens e saída experimental em 4K — não estão disponíveis no momento no Somake. Verifique a página do Imagens do ChatGPT no Somake para ver os parâmetros suportados no momento.
Histórico de Versões
| Versão | Data de Lançamento | Principais Mudanças |
|---|---|---|
| GPT Image 2 | Abr 2026 | Raciocínio nativo, precisão de texto quase perfeita, consistência de personagens, suporte multilíngue (CJK, Hindi, Bengali), resolução até 4K, correção do tom amarelado |
| GPT Image 1.5 | Dez 2025 | Geração 4x mais rápida, melhor seguimento de instruções para edições, melhor renderização de rostos e precisão de cores |
| GPT Image 1 Mini | Out 2025 | Variante de baixo custo do GPT Image 1 |
| GPT Image 1 | Mar 2025 | Primeiro modelo de imagem nativo do GPT-4o; substituiu o DALL-E como padrão; edição conversacional, forte seguimento de instruções |







