ChatGPT Image
GPT Image 2 er OpenAIs mest kraftfulle bilde-modell – 99 % tekstnøyaktighet og opptil 10 bilder per forespørsel. Prøv den nå på Somake AI.
ChatGPT Image AI-generator
Sist oppdatert: 22. april 2026
Gjeldende versjon: GPT Image 2
Eldre versjoner er tilgjengelige via panelet til venstre.
Hurtigoversikt
| Egenskap | Detaljer |
|---|---|
| Modellversjon | GPT Image 2 |
| Utvikler | OpenAI |
| Lanseringsdato | 21. april 2026 |
| Modelltype | Bildegenerering + redigering (multimodal) |
| Kjernefordeler | Nesten perfekt tekstgjengivelse, medfødt resonneringsevne, opptil 4K-oppløsning |
| Best for | Markedsføring, infografikk, produkt-mockups, merkevareinnhold, storyboards |
| Tilgjengelig på Somake | Ja |
Introduksjon
I motsetning til tidligere frittstående verktøy som DALL-E, er denne ChatGPT-bildegeneratoren arkitektonisk integrert med OpenAIs språk- og resonneringssystemer. Dette betyr at den tolker forespørsler med en kontekstuell forståelse som tidligere bildemodeller ikke kunne matche.
Med GPT Image 2 introduserer modellen medfødte resonneringsevner – det OpenAI kaller "tenkemodus" – som lar den planlegge komposisjonen, telle objekter og verifisere layoubegrensninger før bildet genereres. Resultatet er færre mislykkede generasjoner på komplekse oppgaver og et betydelig hopp i nøyaktighet for tekstgjengivelse, som OpenAI rapporterer til over 99 % for både latinske og ikke-latinske skrifter. For team som produserer reklameinnhold, produktark eller instruksjonsgrafikk i store mengder, endrer dette hva AI-bildegenerering faktisk kan brukes til.
GPT Image 2 er sterkest for kommersielle og produksjonsrettede bruksområder: merkevareinnhold, UI-mockups, infografikk, redaksjonelle layouter og storyboards med flere scener. Den er mindre egnet for rent estetisk eller kunstnerisk generering der stilistisk unikhet er hovedmålet – her er modeller som Midjourney fortsatt foretrukket.
Nyheter i GPT Image 2
Viktige endringer fra GPT Image 1.5 (desember 2025):
Medfødt resonnering: Modellen planlegger nå layout, komposisjon og plassering av objekter før generering – aktivert for betalende ChatGPT-abonnenter.
Nøyaktighet i tekstgjengivelse: Takler små UI-etiketter, bildetekster, flerspråklige skrifter (japansk, koreansk, kinesisk, hindi, bengali) og oppsett med flere skrifttyper. En stor forbedring fra 1.5, der tekst bare var "noen ganger brukbar."
Konsistente karakterer på tvers av bilder: Fra og med GPT Image 2 beholder modellen subjektets identitet – inkludert detaljer som tatoveringer og frisyre – over flere genererte bilder.
Fornyet arkitektur: OpenAI beskriver den underliggende modellen som "bygget opp fra grunnen av," med en kunnskapsstopp i desember 2025 for forbedret nøyaktighet i sanntid.
Opptil 4K-oppløsning: Støtter oppløsninger opptil 4096×4096 (maks kant 3840px). Det er kostnadseffektivt å starte med en lavere kvalitetsinnstilling og oppskalere etterpå for å nå 4K.
Websøk i tenkemodus: Modellen kan hente referansebilder og fakta under genereringen for å sikre nøyaktige diagrammer og kontekst fra den virkelige verden.
Fjerning av gult fargeskjær: En vedvarende gjenstand i 1.5-bilder er nå borte i GPT Image 2.
Oppgraderingen er betydelig – ikke bare trinnvis. Tekstgjengivelse og resonnering sammen løser de to mest siterte hindringene for profesjonell bruk. GPT Image 1.5 var allerede kapabel; GPT Image 2 er kommersielt klar for et bredere spekter av oppgaver.
Kjernefunksjoner

Nesten perfekt tekstgjengivelse i genererte bilder
Med GPT Image 2 har tekstnøyaktigheten på tvers av skrifttyper og størrelser nådd over 99 %, inkludert CJK-tegn (kinesisk, japansk, koreansk), hindi, bengali og komplekse tekstoppsett. Dette gjør AI-generert markedsføringsmateriell, menyer, produktetiketter, infografikk og pedagogiske diagrammer brukbare uten manuell redigering – noe tidligere ChatGPT-modeller ikke kunne levere pålitelig.

Flerspråklig bildegenerering
GPT Image 2 gjengir ikke-latinske skrifter nøyaktig i bilder – ikke bare translitterert, men "korrekt rendret med språk som flyter sammenhengende," ifølge OpenAI. Støttede skrifter inkluderer japansk (Kanji/Hiragana/Katakana), koreansk (Hangul), forenklet og tradisjonell kinesisk, hindi (Devanagari) og bengali. For team som produserer lokalt innhold for ulike markeder, fjerner dette behovet for manuell korrigering av ikke-latinsk tekst.

Medfødt resonnering før generering ("Tenkemodus")
GPT Image 2 er OpenAIs første bildemodell med innebygd evne til å tenke. Før den første pikselen tegnes opp, kan modellen planlegge komposisjon, verifisere antall objekter og sjekke romslige begrensninger. I praksis kutter dette ned på antall forsøk på komplekse forespørsler – som layouter med spesifikke plasseringer, rutenett med merket innhold og scener med mange elementer som tidligere modeller ofte satte sammen feil.
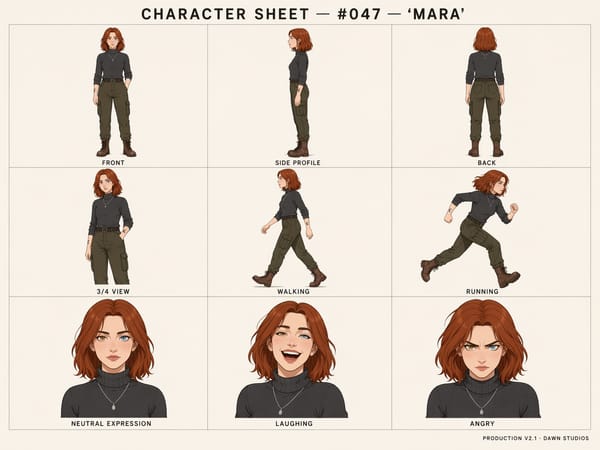
Generering av flere bilder samtidig
Én enkelt forespørsel kan gi opptil åtte sammenhengende bildevariasjoner som deler samme fargepalett, komposisjon og karakteridentitet. Dette erstatter arbeidsflyter der man må generere ett og ett bilde, noe som er perfekt for designere som trenger å se alternativer før de velger en retning.

Karakter- og subjektkonsistens
I GPT Image 2 beholder modellen en konsekvent identitet for subjektet – ansiktstrekk, klær, frisyre og detaljer som tatoveringer – over flere genererte bilder. Dette er svært relevant for storyboard-produksjon, karakterark for spillutvikling og alle arbeidsflyter der samme person eller objekt skal vises i en sekvens.
Beste bruksområder
Markedsføring og annonsemateriell med lesbar tekst
Markedsføringsteam trenger genererte bilder som inkluderer lesbare produktnavn, CTA-er, slagord og merkevaretekst. Med GPT Image 2 rendres disse elementene nøyaktig nok til å brukes direkte. Lag innlegg til sosiale medier, kampanjeflyere og displayannonser der teksten er bakt inn i bildet – deretter kan du oppskalere resultatet hvis du trenger oppløsning klar for trykk.
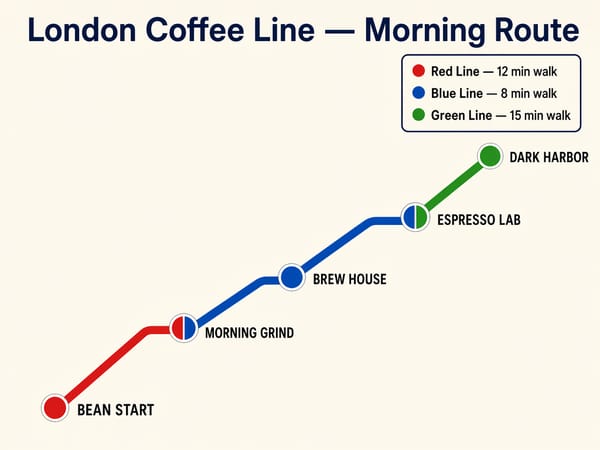
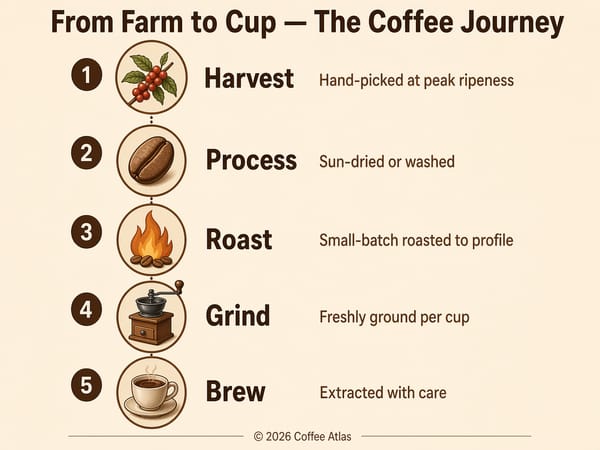
Infografikk, diagrammer og pedagogisk grafikk
Kombinasjonen av resonnering og tekstnøyaktighet gjør GPT Image 2 spesielt god på tett visuelt innhold: prosessdiagrammer, forklarende grafikk, sammenligningskart og merkede kart. Tenkemodusen verifiserer plassering og nøyaktighet før bildet lages, noe som er avgjørende når innholdet må være korrekt og ikke bare se bra ut.

Storyboards og karakterark
Konsistente karakterer over flere bilder er en av de mest praktiske oppgraderingene for kreativ produksjon. Lag et fullstendig karakterark med ulike poseringer og uttrykk ved bruk av opptil 3 referansebilder, eller produser et storyboard der de samme karakterene er lett gjenkjennelige i alle ruter. For strukturerte karakterark kan du prøve karakterark-generatoren som et dedikert utgangspunkt.

Produktbilder og emballasje-mockups
GPT Image 2 håndterer produktfotografering svært godt – med realistisk lyssetting, teksturer og lesbar tekst på emballasje. Lag troverdige frokostblandingsesker, medisinflasker eller produktetiketter med nøyaktig næringsinnhold og strekkoder. For e-handel kan du fjerne bakgrunnen etter generering for å klargjøre produktet for nettbutikken.
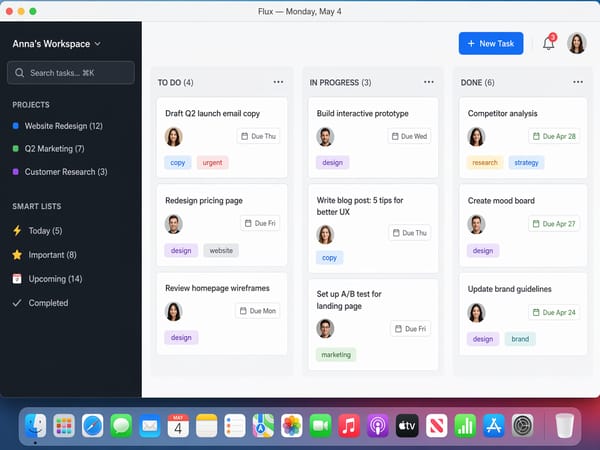
UI-mockups og app-skjermbilder for presentasjoner
Modellen genererer realistiske brukergrensesnitt, nettsider og UI-komponenter som er nøyaktige nok for presentasjoner. Fontgjengivelse, ikonplassering og layoutlogikk håndteres av resonneringslaget. Dette er nyttig for produktsjefer og utviklere som ønsker å prototype visuelle retninger uten designverktøy.
Guide til gode ledetekster (prompts)
Tenkemodusen i GPT Image 2 endrer hvordan ledetekster bør skrives. Modellen planlegger før den genererer – noe som betyr at detaljerte og spesifikke instrukser gir bedre resultater enn vage stilistiske føringer.
Tekst i bilde: Vær eksplisitt
Oppgi stil på skrifttype, størrelseshierarki og nøyaktig tekst du vil ha med. GPT Image 2 håndterer dette bra, men drar nytte av klare instruksjoner fremfor antatte plasseringer.
Eventflyer, mørkeblå bakgrunn, sentrert hvit overskriftstext:
"DESIGN SUMMIT 2026", undertittel under i mindre grå tekst:
"30. april · San Francisco", nettadresse nede til høyre: "designsummit.co"
Minimalistisk layout, geometriske former.Beskriv struktur, ikke bare motiv
GPT Image 2 svarer godt på instruksjoner om komposisjon. Spesifiser hvor objekter skal plasseres, hva bakgrunnen inneholder, og hvilken tekst som skal vises hvor. Resonneringslaget tolker romslige begrensninger som tidligere modeller ignorerte.
Produktbilde av en kaffepose i brunt kraftpapir, sett forfra, hvit bakgrunn,
sort tekstetikett med teksten "Single Origin Ethiopia" i en ren sans-serif font,
indikator for brenningsgrad nederst som viser "Medium", næringsdeklarasjon på
baksiden delvis synlig på høyre kant. Studiolys, lett skygge.
Unngå å be om "mer realistisk" uten detaljer
"Mer realistisk" er ikke en spesielt nyttig instruks for denne modellen. Beskriv heller hva realisme betyr for din oppgave: lystype (golden hour, studio, overskyet), overflatemateriale (matt, blank, ru) eller fotografisk stil (redaksjonell, produktfoto, dokumentar).
Aktivering av tenkemodus for komplekse oppsett
For infografikk, scener med mange objekter og forespørsler som krever nøyaktig antall eller plassering, gir tenkemodus mer pålitelige resultater. I ChatGPT-grensesnittet velger du modellen med tenkemodus. Via API setter du "thinking flag" i forespørselen. Forvent lengre genereringstid – vanligvis 1–3 minutter for komplekse oppgaver – i bytte mot færre feil.
GPT Image 2 vs. Gemini 3 Pro Bilde
| Funksjon | GPT Image 2 | Gemini 3 Pro Image |
|---|---|---|
| Tekstgjengivelse i bilder | Utmerket | Sterk |
| Resonnering / layout-planlegging | Medfødt | Tilgjengelig |
| Karakterkonsistens | Sterk | God |
| Fotorealisme | Sterk | Sterk |
| Kunstnerisk spenn | God | God |
| Maks oppløsning | 4K | 4K |
| Flerspråklig tekst | Utmerket | Sterk |
| Følge instruksjoner | Utmerket | God |
| Hastighet (standardmodus) | ~30–60 sekunder | ~30 sekunder |
Slik bruker du ChatGPT Image på Somake AI
Gå til modellsiden for ChatGPT Image på Somake AI og velg GPT Image 2 fra menyen.
Velg kvalitetsnivå – Lav, Middels eller Høy. Lav gir sterke resultater til en lavere pris og er et godt utgangspunkt for de fleste oppgaver.
Velg bildeformat – velg blant tilgjengelige forhåndsinnstillinger (kvadratisk, liggende, stående).
Velg antall bilder – generer opptil 4 bilder per forespørsel på Somake for å se varianter før du bestemmer deg.
Skriv din ledetekst – vær spesifikk om komposisjon, tekstinnhold, plassering og lys. Detaljerte prompts fungerer best med denne modellen.
Last opp referansebilder (valgfritt) – legg ved opptil 3 referansebilder for redigering, stiloverføring eller karakterkonsistens.
Generer – standardmodus tar 30–60 sekunder.
Merk: Enkelte funksjoner – inkludert tenkemodus, generering av mer enn 4 bilder samtidig og eksperimentell 4K-utgang – er for øyeblikket ikke tilgjengelige på Somake. Sjekk modellsiden på Somake for oppdaterte parametere.
Versjonshistorikk
| Versjon | Lanseringsdato | Viktige endringer |
|---|---|---|
| GPT Image 2 | Apr. 2026 | Medfødt resonnering, nesten perfekt tekstgjengivelse, karakterkonsistens, flerspråklig tekst (CJK, Hindi, Bengali), opptil 4K oppløsning, fjernet gult fargeskjær |
| GPT Image 1.5 | Des. 2025 | 4× raskere generering, bedre på å følge redigeringsinstrukser, bedre ansiktsgjengivelse, forbedret fargenøyaktighet |
| GPT Image 1 Mini | Okt. 2025 | Kostnadseffektiv variant av GPT Image 1 |
| GPT Image 1 | Mar. 2025 | Første innebygde GPT-4o-bildemodell; erstattet DALL-E som standard; samtalebasert redigering, sterk evne til å følge instrukser |







