ChatGPT Image
GPT Image 2 は、文字の再現性99%と驚異的な推論力を備えた OpenAI の最高峰画像モデルです。1つのプロンプトで最大10枚までの生成が可能。今すぐ Somake AI でその実力を体験しましょう。
ChatGPT Image AI画像生成ツール
最終更新日: 2026年4月22日
現在のバージョン: GPT Image 2
旧バージョンは、左側のパネルからご利用いただけます。
概要早見表
| 属性 | 詳細 |
|---|---|
| モデルバージョン | GPT Image 2 |
| 開発元 | OpenAI |
| リリース日 | 2026年4月21日 |
| モデルタイプ | 画像生成 + 編集(マルチモーダル) |
| 主な強み | ほぼ完璧な文字描写、ネイティブ推論、最大4K解像度 |
| 用途に最適 | マーケティングクリエイティブ、インフォグラフィック、製品モックアップ、ブランドコンテンツ、絵コンテ |
| Somakeでの利用 | 可能 |
はじめに
DALL-Eのような従来の単体ツールとは異なり、このChatGPT画像生成ツールは、OpenAIの言語・推論システムと構造的に統合されています。これにより、以前の画像モデルでは難しかった「文脈の理解」に基づいたプロンプトの解釈が可能です。
GPT Image 2では、OpenAIが「思考モード」と呼ぶネイティブ推論機能が導入されました。これにより、画像を生成する前に構図を練り、オブジェクトの数を数え、レイアウトの制約を確認できるようになりました。その結果、複雑な指示でも失敗が少なくなり、文字の描写精度が飛躍的に向上。OpenAIの報告によると、ラテン文字だけでなく非ラテン文字(日本語など)でも99%以上の精度を達成しています。広告クリエイティブ、製品シート、解説用グラフィックを大量に制作するチームにとって、AI画像生成がいよいよ「実戦」で使えるレベルになりました。
GPT Image 2は、ブランドコンテンツ、UIモックアップ、インフォグラフィック、エディトリアルレイアウト、マルチシーンのストーリーボードなど、商業・制作目的のユースケースで最大の力を発揮します。一方で、独自のスタイルを追求する純粋な芸術作品の生成には、依然としてMidjourneyのようなモデルが好まれる傾向にあります。
GPT Image 2の新機能
GPT Image 1.5(2025年12月版)からの主な変更点:
ネイティブ推論: 生成前にレイアウトや構図、配置を計画するようになりました。(ChatGPT有料プランで利用可能)
文字描写精度の向上: 小さなUIラベル、キャプション、多言語(日・韓・中・ヒンディー・ベンガル語)、複数のフォントが混在するレイアウトにも対応。以前の「たまに使える」レベルから劇的に進化しました。
キャラクターの同一性維持: 複数の画像を生成しても、タトゥーや髪型、外見などの細部を含め、対象の個性を一貫して維持できるようになりました。
刷新されたアーキテクチャ: OpenAIによると、モデルは「ゼロから再構築」されており、知識のカットオフは2025年12月。現実世界の描写精度も向上しています。
最大4K解像度出力: 4096×4096(最大辺3840px)までの解像度をサポート。低画質設定で生成してからアップスケーリングするのが、4Kを得るための賢い方法です。
思考モード中のWeb検索: 生成の途中で参考画像や事実を検索し、図解の正確性や現実世界に基づいた情報を反映できます。
黄色かぶりの解消: 1.5の出力で頻繁に見られた特有の黄色い色味が出なくなりました。
今回のアップグレードは単なる改善ではなく、大きな飛躍です。文字描写と推論能力の向上により、プロの現場で障壁となっていた課題が解決されました。GPT Image 2は、ビジネスの現場で即座に投入できるツールです。
主な特徴

画像内の文字描写がほぼ完璧に
GPT Image 2では、文字の正確性が99%以上に達しました。日本語、中国語、韓国語などのCJK文字や、ヒンディー語、ベンガル語、さらには複雑なフォント設定にも対応。これにより、AI生成されたマーケティング資料、メニュー、製品ラベル、インフォグラフィックなどを、手直しなしでそのまま利用することが可能になりました。

多言語での画像生成
GPT Image 2は、画像内の非ラテン文字を正確に描写します。OpenAIによれば、単なる翻字ではなく「文脈に沿った自然な言語として正しくレンダリング」されます。日本語(漢字・ひらがな・カタカナ)、韓国語(ハングル)、中国語(簡体字・繁体字)、ヒンディー語、ベンガル語をサポート。ローカライズが必要なクリエイティブ制作において、手作業による文字の修正が不要になります。

生成前のネイティブ推論(思考モード)
GPT Image 2は、OpenAI初の「考える能力」を備えた画像モデルです。描画を開始する前に、モデルが構図を計画し、オブジェクトの数を確認し、空間的な制約をチェックします。これにより、特定の配置指定、ラベル付きのグリッド、複雑なシーンなど、従来のモデルが苦手としていた指示に対して、やり直し(再生成)の回数を大幅に減らすことができます。
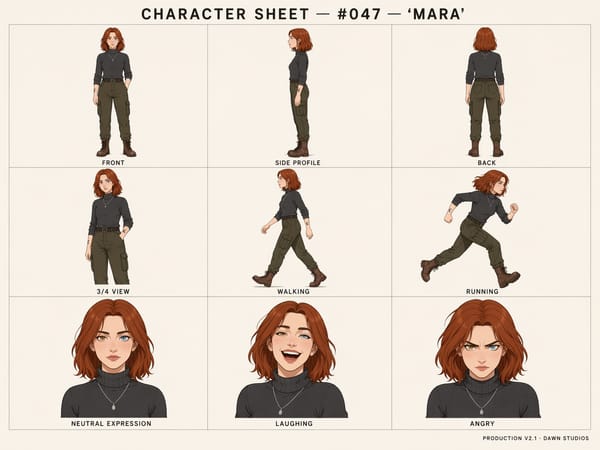
1つのプロンプトから一括生成
1つのプロンプトで、色調、構図、キャラクターの同一性が保たれた最大8パターンのバリエーションを一気に生成できます。デザイナーが方向性を決めるための比較用や、広告のバリエーション制作、ストーリーボードのシーン作成などが格段に効率化されます。

一貫したキャラクターと被写体の維持
GPT Image 2以降、顔の特徴、服装、髪型、タトゥーなどのディテールを維持したまま、複数の画像を生成できるようになりました。ストーリーボードの制作、ゲーム開発用の設定画、同じ人物やオブジェクトを連続したシーンで登場させるワークフローに最適です。
主な活用シーン
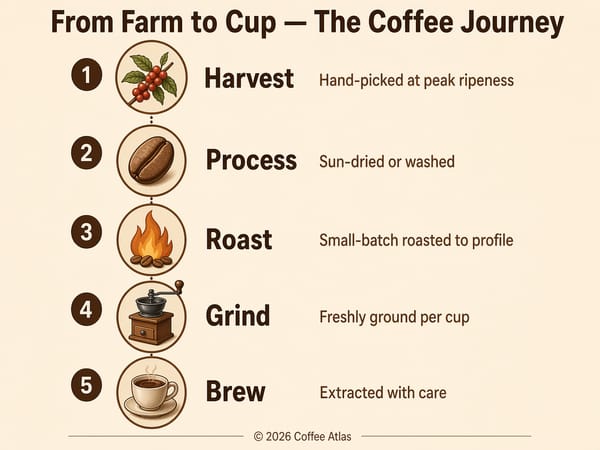
読める文字が入った広告・マーケティング素材の作成
これからは、製品名、CTA(行動喚起)、タグラインなどがはっきりと読み取れる画像が生成できます。SNS投稿、チラシ、バナー広告など、コピーが画像に組み込まれた素材をそのまま制作可能です。印刷用の高解像度が必要な場合は、画像アップスケーラーを使って仕上げましょう。
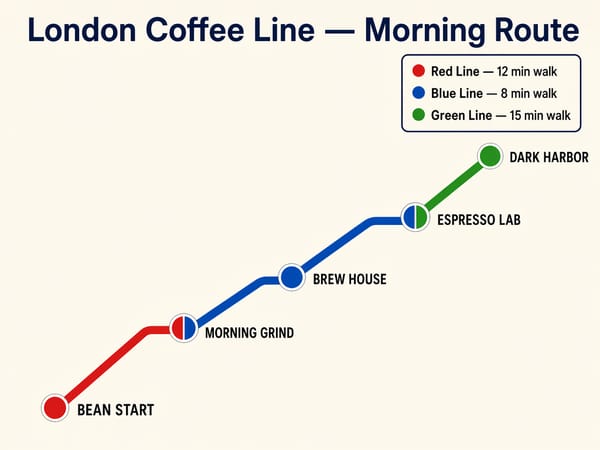
インフォグラフィック、図解、教育用資料の作成
推論能力と文字精度の組み合わせにより、プロセス図、データ解説、比較チャート、ラベル付きマップなどの制作に威力を発揮します。「思考モード」が描画前にラベルの正確性を確認するため、見た目が良いだけでなく、内容としても正しいグラフィックが作成できます。

ストーリーボードとキャラクター設定資料の作成
キャラクターの一貫性は、クリエイティブ制作において最も実用的な進化の一つです。最大3枚の参考画像を使って、異なるポーズや表情のキャラクターシートを作成したり、同じキャラクターが登場する複数パネルのコンテを作成したりできます。専用のツールをお探しの場合は、キャラクターシートジェネレーターから始めるのがおすすめです。

商品写真とパッケージのモックアップ
リアルな照明、表面の質感、そしてパッケージ上のラベルの読みやすさを高いレベルで実現します。シリアルボックス、薬のボトル、成分表やバーコードまで再現された製品ラベルなどのモックアップを生成可能です。ECサイト用には、生成後に背景削除ツールを使って素材化しましょう。
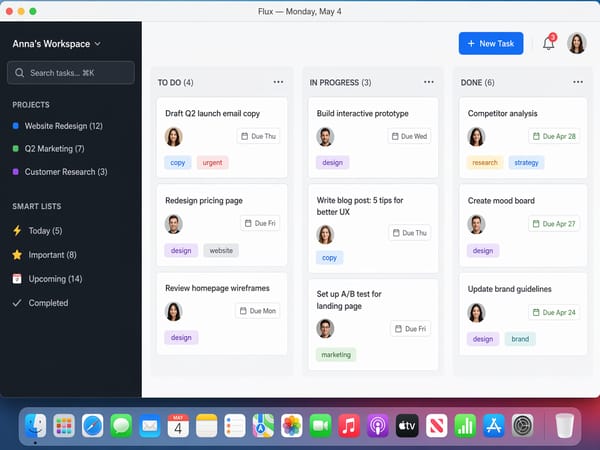
プレゼン用のUIモックアップやアプリ画面
アプリのインターフェースやWebサイトのスクリーンショットを、プレゼンで使用できるレベルの精度で描写します。フォントのレンダリングやアイコンの配置、レイアウトの論理構造は「推論レイヤー」が処理するため、デザインツールを使わなくてもビジュアルのプロトタイプを作成できます。
プロンプトガイド
GPT Image 2の「思考モード」により、プロンプトの書き方が変わります。モデルは描画前に計画を立てるため、曖昧な指示よりも、具体的で詳細な指示を与える方が良い結果に繋がります。
画像内の文字指定:明示的に書く
フォントスタイルやサイズの優先順位、そして表示させたい正確な文字列を指定してください。推論能力により、明確な指示があるほど正確に描写されます。
イベントのフライヤー、ダークネイビーの背景、中央に白い大きな文字で
「DESIGN SUMMIT 2026」と表示、その下に小さめのグレーの文字で
「April 30 · San Francisco」、右下にURL「designsummit.co」を記載。
ミニマルなレイアウト、幾何学的なアクセント模様。主題だけでなく「構造」を説明する
構図に関する指示も重要です。オブジェクトの配置場所、背景の内容、どのテキストをどこに置くかを指定しましょう。以前のモデルでは無視されがちだった空間的な制約を、思考モードが解釈してくれます。
クラフト紙のコーヒー袋の商品写真、正面向き、白背景、清涼感のあるサンセリフ体で
「Single Origin Ethiopia」と書かれた黒いラベル。下部には「Medium」と書かれた
焙煎度の表示バー。右端に裏面の栄養成分表が少し見えている。スタジオ照明、薄い影。
「もっとリアルに」という指示は避ける
単に「もっとリアルに」という言葉はこのモデルには不向きです。代わりに、「照明の種類(ゴールデンアワー、スタジオ、曇天)」、「素材感(マット、光沢、ざらつき)」、「写真のスタイル(エディトリアル、物撮り、ドキュメンタリー)」など、何をもってリアルとするかを具体的に記述してください。
複雑なレイアウトには思考モードを有効にする
インフォグラフィックや多数の物体が登場するシーン、正確な配置が必要な場合は思考モードが有効です。ChatGPTのインターフェースでは思考モデルを選択し、API経由の場合はフラグを設定します。生成には1~3分ほど時間がかかりますが、ミスの少ない正確な画像が得られます。
GPT Image 2 vs. 他社モデル比較
| 機能 | GPT Image 2 | Gemini 3 Pro Image |
|---|---|---|
| 画像内の文字描写 | 非常に優れている | 優れている |
| 推論 / レイアウト計画 | 標準搭載 | 利用可能 |
| キャラクターの同一性 | 非常に高い | 高い |
| 写実性(リアルさ) | 非常に高い | 非常に高い |
| 芸術的スタイルの幅 | 高い | 高い |
| 最大解像度 | 4K | 4K |
| 多言語対応 | 非常に優れている | 優れている |
| 指示への忠実度 | 非常に優れている | 高い |
| 生成速度(通常) | 約30~60秒 | 約30秒 |
Somake AI で ChatGPT Image を使う方法
Somake AI の ChatGPT Image モデルページに移動し、モデル選択メニューから 「GPT Image 2」を選びます。
画質(クオリティ)を選択 — 低、中、高から選べます。 「低」でも十分な精度が得られ、クレジット消費を抑えられるため、多くのタスクで推奨されます。
アスペクト比を設定 — 正方形、横長、縦長など、用途に合わせてプリセットから選択します。
生成枚数を設定 — Somakeでは一度に最大4枚まで生成可能です。バリエーションを確認して最適なものを選びましょう。
プロンプトを入力 — 構図、テキストの内容、物体の配置、ライティングについて具体的に記述してください。詳細なプロンプトほど本領を発揮します。
参考画像をアップロード(任意) — 最大3枚まで添付でき、編集の指示やスタイルの継承、キャラクターの一貫性保持に使用できます。
生成する — 標準モードでは30~60秒で完了します。
注意: 思考モード、4枚を超える一括生成、4K試験的出力などの一部のネイティブ機能は、現在 Somake では対応していません。利用可能な最新パラメータについては、Somake の ChatGPT Image ページをご確認ください。
バージョン履歴
| バージョン | リリース日 | 主な変更点 |
|---|---|---|
| GPT Image 2 | 2026年4月 | ネイティブ推論、ほぼ完璧な文字描写精度、キャラクターの同一性維持、多言語(日中韓・ヒンディー・ベンガル等)対応、最大4K解像度、黄色かぶりの解消 |
| GPT Image 1.5 | 2025年12月 | 生成速度が4倍に向上、編集時の指示への忠実度アップ、人物の顔描写の改善、色の正確性の向上 |
| GPT Image 1 Mini | 2025年10月 | GPT Image 1 の低コスト版 |
| GPT Image 1 | 2025年3月 | 初のネイティブ GPT-4o 画像モデル。DALL-Eに代わり標準採用。対話形式の編集と高いプロンプト忠実度を実現 |







