ChatGPT Image
GPT Image 2 ist das leistungsstärkste Bildmodell von OpenAI — 99 % Textgenauigkeit und bis zu 10 Bilder pro Prompt. Jetzt auf Somake AI ausprobieren.
ChatGPT Image AI-Generator
Zuletzt aktualisiert: 22. April 2026
Aktuelle Version: GPT Image 2
Ältere Versionen sind über das linke Panel verfügbar.
Schnellübersicht
| Attribut | Details |
|---|---|
| Modellversion | GPT Image 2 |
| Entwickler | OpenAI |
| Veröffentlichungsdatum | 21. April 2026 |
| Modelltyp | Bilderzeugung + Bearbeitung (multimodal) |
| Kernstärken | Nahezu perfekte Textdarstellung, natives logisches Denken (Reasoning), bis zu 4K-Auflösung |
| Ideal für | Marketing-Assets, Infografiken, Produkt-Mockups, Branded Content, Storyboards |
| Verfügbar auf Somake | Ja |
Einführung
Im Gegensatz zu früheren eigenständigen Tools wie DALL-E ist dieser ChatGPT-Bildgenerator architektonisch direkt mit den Sprach- und Denksystemen von OpenAI verzahnt. Das bedeutet, dass er Prompts mit einem kontextuellen Verständnis interpretiert, mit dem frühere Bildmodelle nicht mithalten konnten.
Seit GPT Image 2 verfügt das Modell über native Reasoning-Fähigkeiten — den sogenannten "Thinking Mode" von OpenAI. Damit kann das Tool Bildkompositionen planen, Objekte zählen und Layout-Vorgaben prüfen, bevor es mit dem Rendern beginnt. Das Ergebnis sind weniger Fehlversuche bei komplexen Aufgaben und ein enormer Sprung bei der Genauigkeit der Textdarstellung. Laut OpenAI liegt diese nun bei über 99 % für lateinische und nicht-lateinische Schriften. Für Teams, die Werbemittel, Produkndatenblätter oder Infografiken in Serie produzieren, verändert das die Spielregeln für die professionelle Nutzung von KI-Bildern.
GPT Image 2 ist am stärksten bei kommerziellen und produktiven Anwendungsfällen: Branded Content, UI-Mockups, Infografiken, redaktionelle Layouts und Storyboards mit mehreren Szenen. Es eignet sich weniger für rein ästhetische oder künstlerische Zwecke, bei denen stilistische Einzigartigkeit im Vordergrund steht — hier bleiben Modelle wie Midjourney oft die erste Wahl.
Was ist neu in GPT Image 2
Wichtigste Änderungen im Vergleich zu GPT Image 1.5 (Dezember 2025):
Natives Reasoning: Das Modell plant Layout, Komposition und Objektplatzierung vor dem Rendern — aktiviert für zahlende ChatGPT-Abonnenten.
Textdarstellungs-Genauigkeit: Unterstützung für kleine UI-Labels, Bildunterschriften, mehrsprachige Schriften (Japanisch, Koreanisch, Chinesisch, Hindi, Bengali) und Layouts mit gemischten Schriftarten. Ein riesiger Fortschritt gegenüber Version 1.5, in der Text nur "gelegentlich brauchbar" war.
Charakter-Konsistenz über mehrere Bilder: Mit GPT Image 2 behält das Modell die Identität einer Person oder eines Objekts bei — einschließlich Details wie Tattoos und Frisuren — auch wenn mehrere verschiedene Bilder generiert werden.
Überarbeitete Architektur: OpenAI beschreibt das zugrunde liegende Modell als "von Grund auf neu entwickelt", mit einem Wissensstand bis Dezember 2025 für eine bessere Genauigkeit bei realweltlichen Themen.
Bis zu 4K-Auflösung: Unterstützt Auflösungen bis zu 4096×4096 (max. Kantenlänge 3840px). Ein kosteneffizienter Weg zu 4K ist es, mit einer niedrigeren Qualitätseinstellung zu beginnen und das Bild anschließend hochzuskalieren.
Websuche im Thinking Mode: Das Modell kann während der Generierung Referenzbilder und Fakten heranziehen, um die Genauigkeit von Diagrammen und realen Kontexten zu verbessern.
Kein Gelbstich mehr: Ein hartnäckiger Farbartefakt aus 1.5-Outputs wurde in GPT Image 2 beseitigt.
Dieses Upgrade ist ein echter Meilenstein, kein kleiner Zwischenschritt. Textdarstellung und logisches Planen lösen die beiden größten Probleme für die professionelle Anwendung. GPT Image 1.5 war bereits gut; GPT Image 2 ist kommerziell für eine Vielzahl an Aufgaben sofort einsatzbereit.
Kernfunktionen

Nahezu perfekte Textdarstellung in generierten Bildern
Seit GPT Image 2 hat die Textgenauigkeit über verschiedene Schriften und Schriftgrößen hinweg über 99 % erreicht, einschließlich CJK-Zeichen (Chinesisch, Japanisch, Koreanisch), Hindi, Bengali und Layouts mit gemischten Schriften. Damit sind KI-generierte Marketingmaterialien, Menüs, Produktetiketten, Infografiken und Bildungsdiagramme nutzbar, ohne sie händisch korrigieren zu müssen — etwas, das frühere ChatGPT-Bilderzeugungsmodelle nicht zuverlässig leisten konnten.

Mehrsprachige Bilderzeugung
GPT Image 2 stellt nicht-lateinische Schriften in Bildern präzise dar — laut OpenAI werden sie nicht nur transliteriert, sondern "korrekt mit flüssigem Sprachfluss gerendert". Unterstützte Schriften sind unter anderem Japanisch (Kanji/Hiragana/Katakana), Koreanisch (Hangul), vereinfachtes und traditionelles Chinesisch, Hindi (Devanagari) und Bengali. Für Teams, die lokalisierte Werbemittel für verschiedene Märkte erstellen, entfällt damit die manuelle Korrektur von nicht-lateinischen Texten.

Natives Reasoning vor dem Rendern ("Thinking Mode")
GPT Image 2 ist das erste Bildmodell von OpenAI mit integrierten Denkfähigkeiten. Bevor das erste Pixel gerendert wird, kann das Modell die Komposition planen, Objektanzahlen prüfen und räumliche Beschränkungen checken. In der Praxis reduziert das die Anzahl der Versuche bei komplexen Prompts — etwa bei Layouts mit spezifischen Objektplatzierungen, Rastern mit Text oder Szenen mit vielen Elementen, die von früheren Modellen oft falsch zusammengesetzt wurden.
Batch-Generierung mehrerer Bilder aus einem Prompt
Ein einziger Prompt kann bis zu acht stimmige Bildvarianten liefern, die eine einheitliche Farbpalette, Komposition und Charakter-Identität teilen. Dies ersetzt mühsame Einzelgenerierungen für Designer, die verschiedene Optionen sichten möchten, bevor sie sich entscheiden — und für Teams, die verschiedene Anzeigenvarianten oder Storyboard-Frames benötigen.

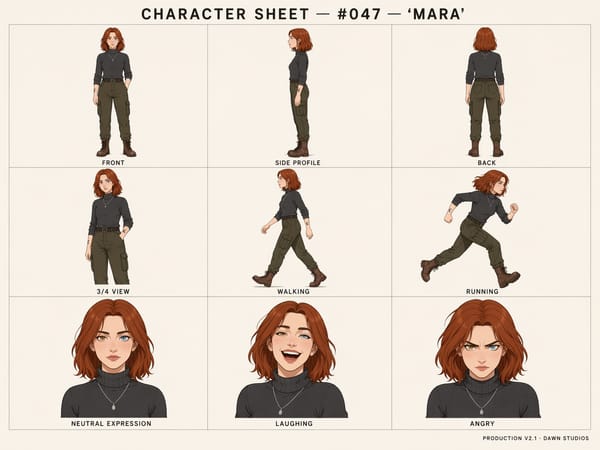
Konsistenz von Charakteren und Objekten
Mit GPT Image 2 behält das Modell die Identität eines Motivs bei — Gesichtszüge, Kleidung, Frisur und markante Details wie Tattoos bleiben über mehrere generierte Bilder hinweg konsistent. Das ist besonders wertvoll für die Storyboard-Produktion, Character Sheets für die Spieleentwicklung und jeden Workflow, bei dem dieselbe Person oder dasselbe Objekt in einer Sequenz erscheinen muss.
Beste Anwendungsfälle
Erstellung von Marketing- und Werbemitteln mit lesbarem Text
Marketing-Teams brauchen Bilder, die Produktnamen, Call-to-Actions (CTAs), Slogans und Markentexte korrekt enthalten. Ab GPT Image 2 werden diese Elemente so präzise gerendert, dass sie direkt für die Produktion genutzt werden können. Erstelle Social-Media-Posts, Flyer und Display-Anzeigen, in denen der Text bereits integriert ist — und nutze dann den Image Upscaler, wenn du druckreife Auflösungen benötigst.
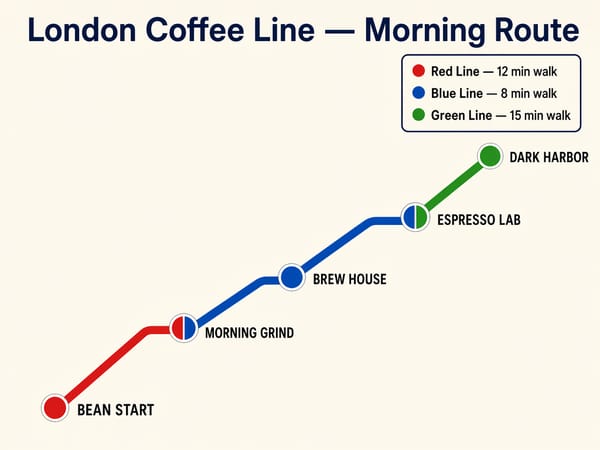
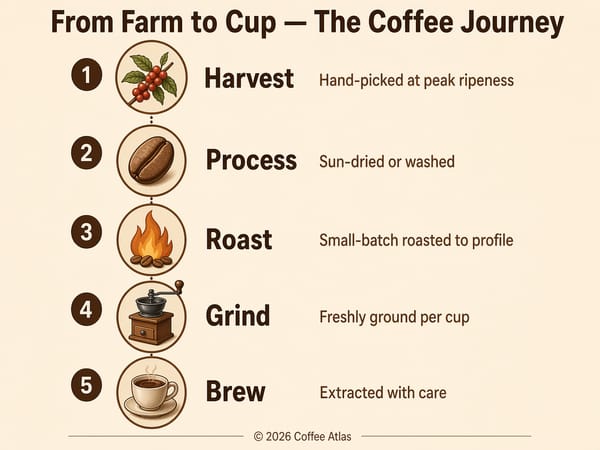
Erstellung von Infografiken, Diagrammen und Lehrmaterialien
Die Kombination aus logischem Denken und präziser Textdarstellung macht GPT Image 2 ideal für komplexe visuelle Inhalte: Prozessdiagramme, Erklärgrafiken, Vergleichstabellen und beschriftete Karten. Der Thinking Mode prüft die Platzierung von Objekten und Beschriftungen vorab, was entscheidend ist, wenn der Inhalt faktisch korrekt und nicht nur optisch ansprechend sein muss.

Produktion von Storyboards und Character Sheets
Die Charakter-Konsistenz über verschiedene Frames hinweg ist einer der praktischsten Fortschritte für die kreative Produktion. Generiere ein komplettes Character Sheet mit verschiedenen Posen und Gesichtsausdrücken unter Verwendung von bis zu 3 Referenzbildern oder erstelle ein mehrteiliges Storyboard, in dem dieselben Charaktere durchgehend auftauchen. Für strukturierte Charakter-Ausgaben kannst du auch den speziellen Character Sheet Generator ausprobieren.

Generierung von Produktfotos und Verpackungs-Mockups
GPT Image 2 beherrscht Produktfotografie-Szenarien hervorragend — realistische Beleuchtung, Oberflächenstrukturen und lesbare Etiketten auf Verpackungen. Erstelle präsentationsreife Müslischachteln, Medikamentenfläschchen oder Produktlabels mit korrekten Inhaltsstoffen und Barcodes. Für E-Commerce-Workflows kannst du nach der Generierung einfach den Background Remover nutzen, um das Asset für dein Listing vorzubereiten.
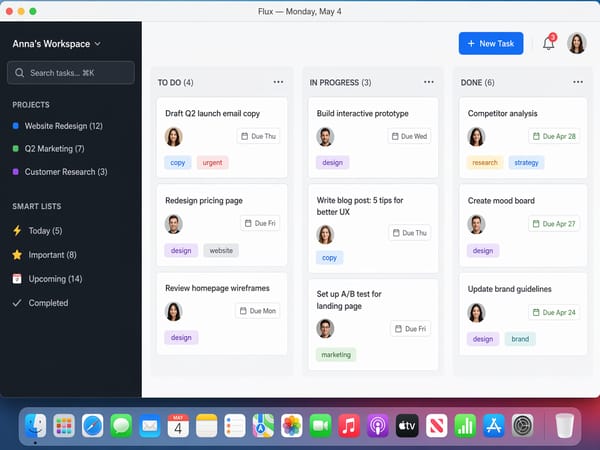
UI-Mockups und App-Screenshots für Präsentationen
Das Modell rendert realistische App-Interfaces, Web-Screenshots und UI-Komponenten präzise genug für Mockups in Präsentationen. Schritdarstellung, Icon-Platzierung und Layout-Logik werden durch die Reasoning-Ebene gesteuert. Das ist nützlich für Produktmanager und Entwickler, die visuelle Richtungen ohne Design-Tools prototypisch umsetzen wollen.
Prompt-Guide
Der Thinking Mode von GPT Image 2 verändert die Art, wie Prompts geschrieben werden sollten. Das Modell plant, bevor es rendert — das bedeutet, dass detaillierte, spezifische Briefings bessere Ergebnisse liefern als vage stilistische Anweisungen.
Text-im-Bild Prompts: Sei explizit
Gib den Schriftstil, die Schriftgrößen-Hierarchie und die exakten Texte an, die erscheinen sollen. GPT Image 2 setzt das genau um, braucht aber klare Anweisungen statt impliziter Vermutungen zur Textplatzierung.
Event-Flyer, dunkelblauer Hintergrund, zentrierter weißer Text in der Überschrift:
"DESIGN SUMMIT 2026", Unterüberschrift darunter in kleinerem grauem Text:
"30. April · San Francisco", Website-URL unten rechts: "designsummit.co"
Minimalistisches Layout, geometrische Akzentformen.Beschreibe die Struktur, nicht nur das Motiv
GPT Image 2 reagiert sehr gut auf Kompositionsanweisungen. Gib an, wo Objekte positioniert werden sollen, was der Hintergrund enthält und welcher Text wo stehen soll. Die Reasoning-Ebene versteht räumliche Vorgaben, die frühere Modelle ignoriert haben.
Produktfoto einer Kaffeetüte aus braunem Kraftpapier, Frontansicht, weißer Hintergrund,
schwarzes Textlabel mit der Aufschrift "Single Origin Ethiopia" in einer sauberen Sans-Serif-Schrift,
Balken für den Röstgrad unten mit der Anzeige "Medium", Nährwerttabelle auf
der Rückseite am rechten Rand teilweise sichtbar. Studiobeleuchtung, leichter Schatten.
Vermeide "realistischer" ohne konkrete Details
"Realistischer" ist für dieses Modell keine hilfreiche Anweisung. Beschreibe stattdessen, was "realistisch" für deinen Anwendungsfall bedeutet: Lichtart (Goldene Stunde, Studio, bewölkt), Oberflächenmaterial (matt, glänzend, rau) oder Fotostil (Clean, Produktfotografie, Dokumentarstil).
Aktivierung des Thinking Mode für komplexe Layouts
Für Infografiken, Szenen mit vielen Objekten und Prompts, die eine genaue Anzahl an Elementen oder präzise Positionierung erfordern, liefert der Thinking Mode zuverlässigere Ergebnisse. Wähle im ChatGPT-Interface die "Thinking"-Variante aus. Über die API setzt du das "Thinking"-Flag in deinem Request. Stelle dich auf eine längere Generierungszeit ein — im Austausch für deutlich weniger Fehler dauert es bei komplexen Aufgaben typischerweise 1–3 Minuten.
GPT Image 2 vs. Gemini 3 Pro Image (ehemals Nano Banana)
| Feature | GPT Image 2 | Gemini 3 Pro Image |
|---|---|---|
| Textdarstellung im Bild | Exzellent | Stark |
| Reasoning / Layout-Planung | Nativ | Verfügbar |
| Charakter-Konsistenz | Stark | Gut |
| Fotorealismus | Stark | Stark |
| Künstlerische Vielfalt | Gut | Gut |
| Max. Auflösung | 4K | 4K |
| Mehrsprachiger Text | Exzellent | Stark |
| Befolgung von Anweisungen | Exzellent | Gut |
| Speed (Standard-Modus) | ~30–60 Sek. | ~30 Sek. |
So nutzt du ChatGPT Image auf Somake AI
Gehe zur ChatGPT Image Modell-Seite auf Somake AI und wähle GPT Image 2 im Dropdown-Menü aus.
Wähle die Qualitätsstufe — Niedrig, Mittel oder Hoch. "Niedrig" liefert bereits starke Ergebnisse bei geringeren Credit-Kosten und ist ein guter Startpunkt.
Wähle das Seitenverhältnis — entscheide dich für eine der Vorlagen passend zu deinem Format (Quadrat, Querformat, Porträt).
Lege die Bildanzahl fest — generiere bis zu 4 Bilder pro Anfrage auf Somake, um Variationen zu vergleichen.
Schreibe deinen Prompt — sei spezifisch bei Komposition, Textinhalt, Platzierung und Licht. Detaillierte Prompts funktionieren hier am besten.
Referenzbilder hochladen (optional) — hänge bis zu 3 Bilder für Bearbeitungen, Stil-Transfers oder Charakter-Konsistenz an.
Generieren — der Standardmodus dauert etwa 30–60 Sekunden.
Hinweis: Einige native Funktionen des Modells — wie der Thinking Mode, Batch-Generierung über 4 Bilder hinaus und experimentelle 4K-Ausgabe — sind derzeit nicht direkt auf Somake verfügbar. Prüfe die ChatGPT Image Seite auf Somake für die aktuell unterstützten Parameter.
Versionsverlauf
| Version | Veröffentlichungsdatum | Wichtige Änderungen |
|---|---|---|
| GPT Image 2 | Apr 2026 | Natives Reasoning, nahezu perfekte Textgenauigkeit, Charakter-Konsistenz, mehrsprachiger Text (CJK, Hindi, Bengali), bis zu 4K-Auflösung, Gelbstich entfernt |
| GPT Image 1.5 | Dez 2025 | 4x schnellere Generierung, bessere Befolgung von Edit-Anweisungen, optimierte Gesichterdarstellung, bessere Farbtreue |
| GPT Image 1 Mini | Okt 2025 | Kosteneffiziente Variante von GPT Image 1 |
| GPT Image 1 | Mär 2025 | Erstes natives GPT-4o Bildmodell; ersetzte DALL-E als Standard; interaktive Bearbeitung, starke Befolgung von Anweisungen |







