ChatGPT Image
GPT Image 2 är OpenAI:s vassaste bildmodell – 99 % textprecision, inbyggt logiskt tänkande och upp till 10 bilder per prompt. Testa nu på Somake AI.
ChatGPT Image AI-bildgenerator
Senast uppdaterad: 22 april 2026
Nuvarande version: GPT Image 2
Tidigare versioner är tillgängliga via panelen till vänster.
Snabböversikt
| Attribut | Information |
|---|---|
| Modellversion | GPT Image 2 |
| Utvecklare | OpenAI |
| Lanseringsdatum | 21 april 2026 |
| Modelltyp | Bildgenerering + redigering (multimodal) |
| Huvudsakliga styrkor | Nästintill perfekt textåtergivning, inbyggt logiskt tänkande, upp till 4K-upplösning |
| Bäst för | Marknadsföringsmaterial, infografik, produktmockups, varumärkesinnehåll, storyboards |
| Tillgänglig på Somake | Ja |
Introduktion
Till skillnad från tidigare fristående verktyg som DALL-E, är denna ChatGPT-bildgenerator arkitektoniskt integrerad med OpenAI:s språk- och logiksystem. Det innebär att den tolkar dina prompts med en nivå av kontextuell förståelse som tidigare bildmodeller helt enkelt inte kunde matcha.
I och med GPT Image 2 introduceras inbyggda resonemangsförmågor – vad OpenAI kallar "thinking mode" – som gör att den kan planera komposition, räkna objekt och verifiera layoutbegränsningar innan den börjar skapa bilden. Resultatet blir färre misslyckade generationer vid komplexa instruktioner och ett enormt hopp i textprecision, som enligt OpenAI nu ligger på över 99 % för både latinska och icke-latinska skrifter. För team som producerar reklammaterial, produktblad eller instruktionsgrafik i stora volymer förändrar detta helt vad AI-bildgenerering faktiskt kan användas till.
GPT Image 2 är som starkast för kommersiella och produktionsinriktade användningsområden: varumärkesinnehåll, UI-mockups, infografik, redaktionell layout och storyboards med flera scener. Den är mindre lämpad för rent estetiskt skapande eller finkonst där stilistisk unikhet är huvudmålet – där förblir modeller som Midjourney förstahandsvalet.
Vad är nytt i GPT Image 2
Viktiga ändringar från GPT Image 1.5 (december 2025):
Inbyggt logiskt tänkande: Modellen planerar nu layout, komposition och objektplacering innan den renderar bilden – aktiverat för betalande ChatGPT-prenumeranter.
Textprecision: Hanterar små UI-etiketter, bildtexter, flerspråkiga skrifter (japanska, koreanska, kinesiska, hindi, bengali) och layouter med blandade typsnitt. En rejäl uppgradering från 1.5, där text bara var "ibland användbar".
Konsekventa karaktärer: I GPT Image 2 behåller modellen subjektets identitet – inklusive detaljer som tatueringar och frisyrer – över flera genererade bilder.
Omarbetad arkitektur: OpenAI beskriver den underliggande modellen som "ombyggd från grunden", med en kunskapsgräns fram till december 2025 för ökad verklighetstrogenhet.
Upp till 4K-upplösning: Stöder upplösningar upp till 4096×4096 (max kant 3840px). Att börja med en lägre kvalitetsinställning och skala upp efteråt är ett kostnadseffektivt sätt att nå 4K.
Webbsökning i "thinking mode": Modellen kan hämta referensbilder och fakta mitt i genereringen för att säkerställa korrekta diagram och verklighetsförankrad kontext.
Eliminering av gulstick: En envis färgton som fanns i 1.5-bilder är nu helt borta i GPT Image 2.
Uppgraderingen är substantiell, inte bara steglös. Textåtergivning och logiskt tänkande adresserar tillsammans de två största hindren för professionell användning. GPT Image 1.5 var kompetent; GPT Image 2 är redo för skarpa kommersiella uppdrag.
Huvudfunktioner

Nästintill perfekt textåtergivning i genererade bilder
Från och med GPT Image 2 har textprecisionen för olika skrifter och typsnittsstorlekar nått över 99 %, inklusive CJK-tecken (kinesiska, japanska, koreanska), hindi, bengali och layouter med blandade typsnitt. Detta gör att AI-genererat marknadsföringsmaterial, menyer, produktetiketter, infografik och pedagogiska diagram kan användas direkt utan manuell efterredigering – något tidigare ChatGPT-modeller inte kunde leverera pålitligt.

Flerspråkig bildgenerering
GPT Image 2 renderar icke-latinska skrifter korrekt inuti bilderna – inte bara translittererat, utan "korrekt renderat med ett språk som flyter sammanhängande," enligt OpenAI. Bland de skrifter som stöds finns japanska (Kanji/Hiragana/Katakana), koreanska (Hangul), förenklad och traditionell kinesiska, hindi (Devanagari) och bengali. För team som producerar lokaliserat material för olika marknader tar detta bort behovet av manuell korrigering av icke-latinsk text.

Inbyggt logiskt tänkande före rendering ("Thinking Mode")
GPT Image 2 är OpenAI:s första bildmodell med inbyggd tankeförmåga. Innan den första pixeln skapas kan modellen planera kompositionen, kontrollera antal objekt och verifiera rumsliga begränsningar. I praktiken minskar detta antalet försök på komplexa prompts – som layouter med specifika objektplaceringar, rutnät med etiketter och scener med många element som tidigare modeller ofta misslyckades med att sätta ihop korrekt.
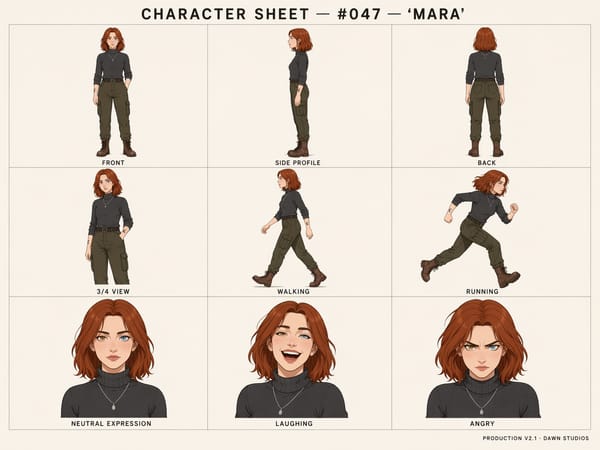
Batchgenerering av flera bilder från en enda prompt
En enda prompt kan ge upp till åtta sammanhängande bildvariationer som delar samma färgpalett, komposition och karaktärsidentitet. Detta ersätter arbetsflöden där man genererar en bild i taget, vilket är perfekt för designers som behöver se olika alternativ innan de väljer riktning, eller för team som skapar flera varianter av annonser eller storyboards.

Konsekventa karaktärer och subjekt över flera bilder
I GPT Image 2 bibehåller modellen en konsekvent identitet för subjektet – ansiktsdrag, kläder, frisyr och särdrag som tatueringar – över flera genererade bilder. Detta är ovärderligt för storyboard-produktion, karaktärsblad för spelutveckling och alla arbetsflöden där samma person eller föremål behöver synas i en sekvens.
Bästa användningsområden
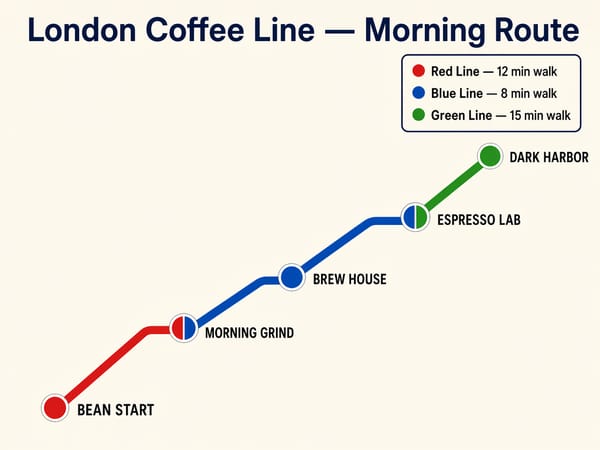
Skapa marknadsföring och annonser med läsbar text
Marknadsföringsteam behöver genererade bilder som innehåller läsbara produktnamn, call-to-actions, taglines och varumärkestext. Med GPT Image 2 är dessa element tillräckligt exakta för att användas i skarpt läge utan handpåläggning. Skapa inlägg för sociala medier, flygblad och displayannonser där texten är inbyggd i bilden – och skala upp ditt resultat om du behöver upplösning för tryck.
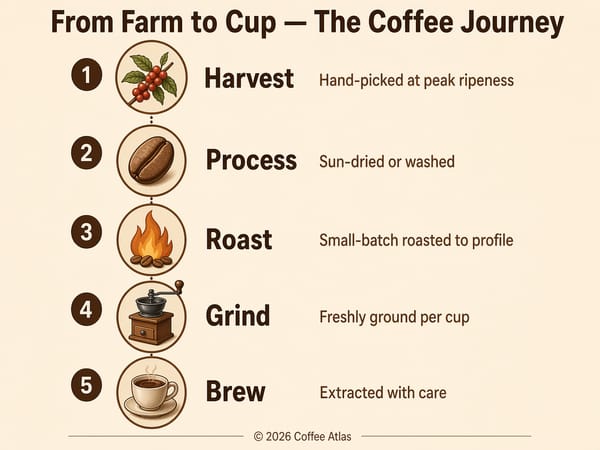
Bygga infografik, diagram och pedagogisk grafik
Kombinationen av logiskt tänkande och textprecision gör GPT Image 2 särskilt lämpad för tätt visuellt innehåll: processdiagram, förklarande grafik, jämförelsediagram och märkta kartor. "Thinking mode" verifierar objektens placering och etiketternas noggrannhet före rendering, vilket är avgörande när innehållet måste vara faktamässigt korrekt, inte bara snyggt.

Producera storyboards och karaktärsblad
Konsekventa karaktärer över flera bildrutor är en av de mest praktiska uppgraderingarna för kreativ produktion. Skapa ett komplett karaktärsblad med olika poser och uttryck med hjälp av upp till 3 referensbilder, eller producera en storyboard där samma karaktärer ser likadana ut genom hela serien. För strukturerade karaktärsblad, prova vår dedikerade karaktärsgenerator.

Generera produktbilder och förpackningsmockups
GPT Image 2 hanterar produktfotografering galant – med realistisk ljussättning, texturer och läsbara etiketter på förpackningar. Skapa pitch-redo flingpaket, medicinflaskor eller produktetiketter med korrekta näringsvärden och streckkoder. För e-handel kan du sedan ta bort bakgrunden efter genereringen för att förbereda bilden för din webbshop.
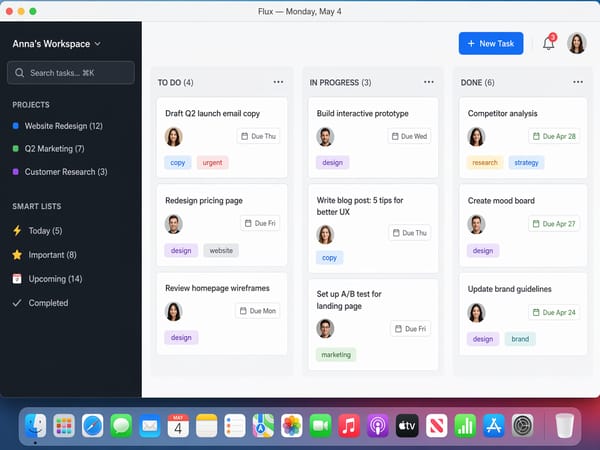
UI-mockups och app-screenshots för presentationer
Modellen skapar realistiska gränssnitt, webbplatsbilder och UI-komponenter som är tillräckligt bra för presentationer. Typsnitt, ikonplacering och layoutlogik hanteras av det logiska lagret. Detta är mycket användbart för produktägare och utvecklare som vill prototyptesta visuella spår utan att använda designverktyg.
Guide för prompts
GPT Image 2:s "thinking mode" förändrar hur man bör skriva sina prompts. Modellen planerar innan den skapar – vilket innebär att detaljerade instruktioner ger mycket bättre resultat än vaga stilistiska anvisningar.
Text-i-bild prompts: Var tydlig
Ange typsnittsstil, storlekshierarki och exakt den text du vill ha med. GPT Image 2 hanterar detta bra men fungerar bäst med tydliga instruktioner snarare än underförstådda placeringar.
Event flyer, mörkblå bakgrund, centrerad vit rubriktext med texten
"DESIGN SUMMIT 2026", underrubrik under i mindre grå text med texten
"April 30 · San Francisco", webbadress längst ner till höger: "designsummit.co"
Minimalistisk layout, geometriska former.Beskriv struktur, inte bara motivet
GPT Image 2 svarar bra på kompositionsinstruktioner. Ange var objekt ska placeras, vad bakgrunden innehåller och vilken text som ska synas var. Det logiska lagret tolkar rumsliga instruktioner som tidigare modeller ofta ignorerade.
Produktbild av en kaffepåse i brunt kraftpapper, vänd framåt, vit bakgrund,
svart etikett med texten "Single Origin Ethiopia" i ett rent sans-serif-typsnitt,
en stapel för rostningsgrad längst ner som visar "Medium", näringsdeklaration på
baksidan delvis synlig vid högerkanten. Studioljus, lätt skugga.
Undvik att be om "mer realistiskt" utan detaljer
"Mer realistiskt" är inte en särskilt hjälpsam instruktion för den här modellen. Beskriv istället vad realism innebär för just din bild: ljustyp (gyllene timmen, studioljus, mulet), ytmaterial (matt, glansigt, grovt) eller fotografisk stil (redaktionellt, produktfoto, dokumentärt).
Aktivera "Thinking Mode" för komplexa layouter
För infografik, scener med många objekt eller prompts som kräver ett visst antal element, ger "thinking mode" mer pålitliga resultat. I ChatGPT-gränssnittet väljer du modellvarianten för logiskt tänkande. Via API sätter du flaggan för "thinking" i din begäran. Räkna med något längre genereringstid – vanligtvis 1–3 minuter för komplexa uppgifter – i utbyte mot färre fel.
GPT Image 2 vs. Nano Banana Pro
| Funktion | GPT Image 2 | Gemini 3 Pro Image |
|---|---|---|
| Textåtergivning i bilder | Utmärkt | Stark |
| Logik / layoutplanering | Inbyggd | Tillgänglig |
| Konsekventa karaktärer | Stark | Bra |
| Fotorealism | Stark | Stark |
| Artistisk bredd | Bra | Bra |
| Max upplösning | 4K | 4K |
| Flerspråkig text | Utmärkt | Stark |
| Följsamhet till instruktioner | Utmärkt | Bra |
| Hastighet (standardläge) | ~30–60 sekunder | ~30 sekunder |
Hur du använder ChatGPT Image på Somake AI
Gå till sidan för ChatGPT Image på Somake AI och välj GPT Image 2 i rullistan för modeller.
Välj kvalitetsnivå – Låg, Medium eller Hög. Låg ger starka resultat till en lägre kreditkostnad och är en bra startpunkt för de flesta uppgifter.
Välj bildformat – välj bland de tillgängliga förinställningarna baserat på ditt format (kvadratisk, liggande, stående).
Ange antal bilder – generera upp till 4 bilder per förfrågan på Somake för att se olika varianter innan du bestämmer dig.
Skriv din prompt – var specifik med komposition, textinnehåll, objektplacering och ljus. Detaljerade prompts fungerar bättre med denna modell.
Ladda upp referensbilder (valfritt) – bifoga upp till 3 referensbilder för redigeringar, stilöverföringar eller för att behålla samma karaktär i olika bilder.
Generera – i standardläget tar det ca 30–60 sekunder.
Notera: Vissa modellspecifika funktioner – som "thinking mode", batchgenerering över 4 bilder och experimentell 4K-upplösning – är för närvarande inte tillgängliga på Somake. Se sidan för ChatGPT Image på Somake för de stödda parametrarna just nu.
Versionshistorik
| Version | Lanseringsdatum | Viktiga ändringar |
|---|---|---|
| GPT Image 2 | Apr 2026 | Inbyggt logiskt tänkande, nästintill perfekt textprecision, konsekventa karaktärer, flerspråkig text (CJK, hindi, bengali), upp till 4K, eliminerat gulstick |
| GPT Image 1.5 | Dec 2025 | 4x snabbare generering, bättre på att följa instruktioner vid redigering, förbättrad ansiktsåtergivning och färgnoggrannhet |
| GPT Image 1 Mini | Okt 2025 | Kostnadseffektiv variant av GPT Image 1 |
| GPT Image 1 | Mar 2025 | Första inbyggda GPT-4o-bildmodellen; ersatte DALL-E som standard; konversationsbaserad redigering, stark följsamhet till prompts |







